1. 코딩테스트 연습 - 해시 - 완주하지 못한 선수
- 문제 분석, 어떤 자료구조와 알고리즘 선택하면 적합한지, 나아가 코드 실제 작성해보기
지문을 자세하게 살펴보자. 문제를 만났을 때, 문제로 부터 받은 첫인상은 매우 중요.
- 문제의 크기는 무엇에 지배되는 지,
- 어떤 제약사항이 있는지.
문제 접근
- 수많은 사람들이 선수들이 마라톤에 참여
- 단 한 명의 선수를 제외하고는 모든 선수가 마라톤을 완주
- 마라톤에 참여한 선수들의 이름이 담긴 배열 participant와 완주한 선수들의 이름이 담긴 배열 completion이 주어질 때,
-
완주하지 못한 선수의 이름을 return 하도록 solution 함수를 작성해주세요
- 제한사항
- 마라톤 경기에 참여한 선수의 수는 1명 이상 100,000명 이하
- participant의 길이는, 10만 이하를 가질 것이네.
- completion의 길이는 participant의 길이보다 1 작다.
- 참가자의 이름은 1개 이상 20개 이하의 알파벳 소문자로 이루어져 있다.
-
참가자 중에는 동명이인이 있을 수 있다.
- 동명이인 조건이 없었다면, 집합으로 구해서 차집합으로 구해버리면 되는데, 이 조건을 인해 접근 방법이 달라짐
- 입출력 에시도 잘 살펴보기
문제 들어가기
- 동명이인이 있을 수 있다고 했다.
- 어떤 특정한 이름의 사람 수를 세고, 그 이름의 완주한 선수를 세서, 같으면 그 사람들은 다 완주한 것
- 그런데 딱 한명, 완주하지 못한 선수, 예를 들어 김철수라면. 김철수가 참가자 목록에는 3번 들어있고, 완주한 사람에 번 들어있다면 , 그 사람은 안주하지 못한 것
- 이름에 대해서 어떤 수를 기록하고 저장할 수 있는 그런 구조를 원하게 된다.
- 그게 이 문제의 범주인 해쉬와 밀접하게 관련이 있다.
자료구조와 알고리즘의 선택
- 만약 이름 대신 번호가 주어졌다면 ?
- 선형 배열이 가능해지겠다. (최대 10만인)
- 여기서는 배열을 이용하지 못할 거야. 만약 가능한 모든 이름의 조합의 수를 배열로 나타내려고 하면, 영문 알파벳 26자. 대강 26의 20승 만큼의 배열을 잡아야 한다.
- 번호 말고 다른 것 (ex:문자열)로 접근할 수 있는 좋은 자료구조는 없나요 ?
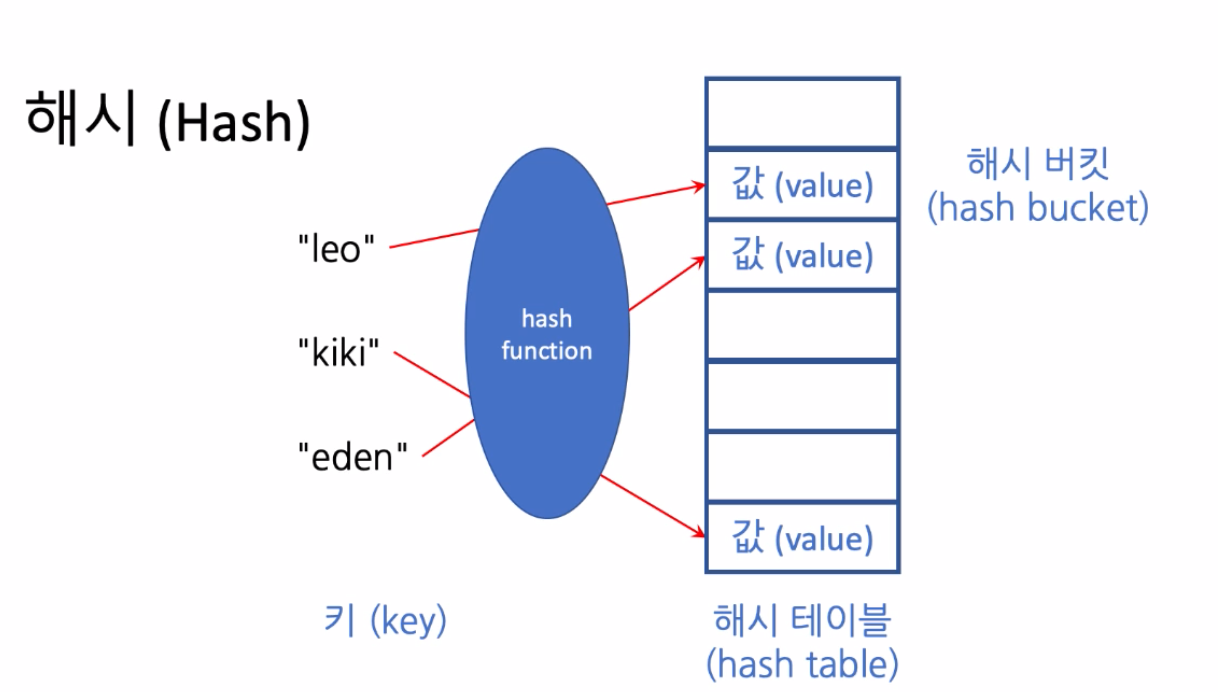
해시(Hash)
- 배열의 경우 인덱스가 주어지면 몇 번째 원소로 바로 찾아갈 수 있는 그런 구조가 주어진다.
- 인덱스 말고 정수로 주어진 인덱스 말고, 문자열 같은 다른 걸로 찾아갈 수 있는 자료구조 -> Hash
- 해쉬에서는 왼쪽에 있는 사람들의 이름을 키로하고, 해쉬 테이블이라고 부르는 어떤 저장 공간 내에다가 키들이 어느 위치에 있을 지를 정해서, 해쉬 테이블 안에 값을 저장하는 구조다.
-
인덱스 대신에 원소를 찾아가려는 사람 이름을 키라고 부른다.
- 가급적이면 서로 다른 칸에 들어갈 수 있도록 보장하려는 hashFunction
- 버켓의 수가 많을수록 서로 다른 버켓에 가능성이 높아진다.
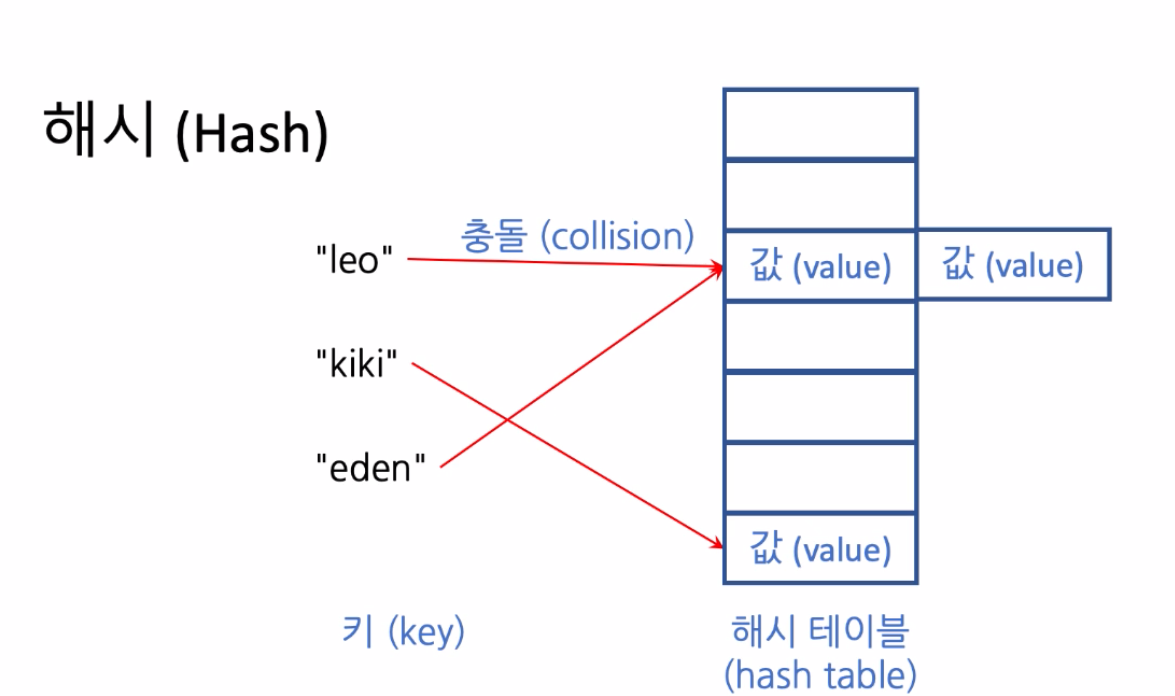
- 같은 칸에 사상되는 경우도 물론 생길 수 있어. 이런 상황을 collision이라고 부른다.
- 예를 들면, 같은 칸에 옆에 또 다른 버켓을 놓는 방법도 있다.
문제의 풀이 예제
- participant 네 명의 선수 참여. mislav가 두명
- completion은 세명의 선수. mislav가 한 명만 완주. participant를 보자
- mislav라는 문자열의 1을 대응. 이걸 해쉬 테이블에 등록
- stanko라는 이름에도 1이 기록
- 또 다시 mislav가 등장 -> mislav에 대응 -> 2로 만든다
- 마지막 ana -> 1의 관계 대응된 관계 기록
그 다음 completion을 보자
- stanko 완주했네 그럼 stanko가 1이었던 값이 0으로 1만큼 감소
- ana라는 선수가 완주,ana에 대응되어있던 값도 1에서 0으로 감소
-
마지막 mislav에 대응되어있던 값이 2에서 1만큼 감소. 그럼 끝
- 지금 해쉬 테이블에 등록되어 있는 이름 중에, 한 선수만 , mislav만 1을 가짐. 따라서
-
리턴값은 mislav가 된다.
- 이런 흐름을 그대로 코드로 옮기면 답을 산출할 수 있다.
- 해쉬 테이블에 문제열로 이루어진 사람들의 이름과, 그 이름이 participant에 등장한 횟수를 세서 해쉬테이블에 기록하고,
- completion 을 배열에 보면서 대응된 값들을 조절해가면서 찾아내는 알고리즘
python 풀이 예제보기
-
어떻게 해쉬라는 기법을 이용해서 효과적으로 이용 ?
- python에는 사전이란 구조가 있다.
- ex )
d = {"leo":30, "kiki":62,"eden":5} - x = d[“leo”]
- d[“leo”]= 58
-
파이썬에서는 사전의 원소들을 해시를 이용해 O(1) 시간에 접근 가능
- 이 문제가 독특한 이유는 동명이인이 있을 수 있기 때문이다.
- participant에는 참가자 선수들 이름이 담김
- completion에는 완주한 선수들의 이름이 담겨있다.
- 각각의 이름에 대해서, 이 이름이 몇 번 나왔는지를 세고,
- 그 다음 completion에 이름을 보고, 몇명이나 완주했는지를 세면, 딱 한명만 완주하지 못한 걸 가려낼 수 있다.
그 전에 딕셔너리 공부 잠깐 하고 가자.
wintable = {
'가위' : '보',
'바위' : '가위',
'보' : '바위',
}
print(wintable['가위'])
# 딕셔너리 추가
dict['three'] = 3
# 리스트와 달리 값을 넣어주면 된다.
# 딕셔너리 수정
dict['one'] = 11
# 딕셔너리 삭제
del(dict['one'])
### 딕셔너리와 반복문
for key in ages.keys(): # keys() 생략 가능
print(key)
for value in ages.values():
print(value)
# key,value 둘다 가져올 수 있다.
for key, value in ages.items():
print('{}의 나이는 {} 입니다'.format(key, value))
List Dictionary
- 생성 list = [ 1, 2 ,3 ] dict = { ‘one’:1, ‘two’:2 }
- 호출 list[ 0 ] dict[ ‘one’ ]
- 삭제 del( list[ 0 ] ) del( dict[ ‘one’ ] )
- 개수 확인 len( list ) len( dict )
- 값 확인 2 in list ‘two’ in dict.keys( )
- 전부 삭제 list.clear( ) dict.clear(
차이점
- List Dictionary
- 순서 삭제 시 순서가 바뀌기 때문에 인덱스에 대한 값이 바뀐다 key로 값을 가져오기 때문에 삭제 여부와 상관없다
- 결합 list1 + list2 dict1.update( dict2 )
Dictionary comprehension
students = ["태연","진우","정현","하늘","성진"]
for number, name in enumerate(students):
print("()번의 이름은 () 입니다.".format(number,name))
students_dict = {"{}번".format(number+1):name for number,name in enumerate(students)}
# key: "{}번.fomat(number+1)"
# value : name
zip
- 두 개 이상의 리스트나 스트링을 받아들여서 인덱스에 맞게 for in문에서 하나씩 던져줄 수 있다.
students = ["태연","진우","정현","하늘","성진"]
scores = [86,92,78,90,100]
for x,y in zip(studnets,scores):
print(x,y)
score_dic = {students: score for students, score in zip(students,scores)}
문제 풀이
def solution(participant,completion):
d = {} # 빈 사전을 만들고
for x in participant :
# key로 value를 얻어내는 함수가 get이다.
# get(x,'default값') 딕셔너리에 x가 없을 시 default 값을 출력
d[x] = d.get(x,0) + 1
# 처음 등장하면 1로 만들고, 처음 등장한게 아니면, 원래 있던 value에 1을 더해줌
for x in completion:
d[x] -=1
# 단 한명만 완주하지 못했으므로, 그리고 그게 1명이라고 했으므로
dnf = [k for k, v in d.items() if v >0]
answer = dnf[0]
return answer
- 해쉬를 어떻게 이용하느냐가 관건이다.
- 알고리즘의 복잡도를 살펴보자.
- 코드의 실행이 solution 함수에 들어오면, 이 함수의 몸체 안에는 순환문이 2개가 들어있다.
- 3,4행에 걸쳐있는 순환문의 복잡도는 participant라는 배열의 길이에 비례한다.
- 5,6행에 걸쳐있는 순환문도 completion의 배열의 길이에 비례한다.
-
7행도 list comprehension에 들어있는데, 상수시간처럼 보이지만, 그렇지 않다. 이 역시 사전의 길이에 비례하는 연산
- 결국 이 함수 전체의 시간복잡도는 배열의 길이, n에 비례하는 linear time 이다.
- 해쉬테이블이 키를 기준으로, 인덱스가 아닌 사람들의 문자열에 해쉬 테이블을 상수 시간에 읽고 쓸 수 있었기 때문에 가능했다.
-
해쉬라는 구조를 언제 이용하냐, 해쉬 프로그래밍의 기초를 연습해본 것.
- 다른 사람의 풀이를 봤더니, 다른 생각을 전개해서 풀어놓은 코드들도 있었다.
- 그 복잡도를 살펴보자
Q) 정렬을 이용한다면 ?
- 알파벳 원소 순서에 따라 정렬한다면 ?
- 같은 이름 중에, participant에는 있고, comprehension에는 없는 데에서 차이가 난다.
- 예를 들면 이런 코드가 가능하다.
def solution(participant, completions):
participant.sort()
completion.sort()
for i in range(len(completion)):
if participant[i] != complehension[i]:
return participant[i]
return participant[len(participant)-1]
- 각 리스트를 정렬한 뒤, participant에 등장한 원소와 complehension에 등장한 원소와 달라지는 곳을 찾아서, 그 자리를 리턴한다는 식으로 많이 있더라.
- 근데 이건, 코드의 복잡도는 2행과 3행의 배열들을 크기 순으로 정렬하는,
- 그 연산은 sorting의 최적 알고리리즘도 O(nlogn)에 비례.
- 배열을 정렬해서 풀면, linear 타임있었던 것에 비해서, 정렬을 이용하면 더 느리게 되는 것.
- 테스트는 통과하지만 그 이유는 현실적으로 nlogn 복잡도 알고리즘과 n의 복잡도를 가진 알고리즘의 실행 시간을 변별하기 어렵기 때문이다.
- 이 문제의 요점은 해쉬를 이용해서 키로 인해서 원소로 접근하는 것이 상수시간에 이루어질 수 있다는 것에 착안한 것.
참고자료 [프로그래머스]https://programmers.co.kr/learn/courses/9877 [딕셔너리공부]https://programmers.co.kr/learn/courses/2