1.String
목차
- 문자열
- 패턴 매칭
1.1 문자열 표현
컴퓨터에서의 문자 표현 : 글자 A를 메모리에 저장하는 방법
- 메모리는 숫자만을 저장할 수 있기 때문에 A라는 글자의 모양 그대로 비트맵을 저장하는 방법을 사용하지 않는 한 각 문자에 대해서 대응되는 숫자를 정해 놓고 이것을 메모리에 저장하는 방법이 사용될 것
- 코드체계: ex) 영어가 대소문자 합쳐서 52이므로 6비트면 모두 표현할 수 있음
네트워크가 발전하며 서로 간의 정보를 주고 받을 때 정보를 달리 해석한다는 문제가 생김 이를 피하기 위해 표준안을 제정 -> 그게 ASCII 인코딩 표준
-
아스키 : 7비트 인코딩, 128문자로 이루어짐, A는 65
-
확장 아스키 : 표준 문자 이외에 악센트, 도형, 특수 문자, 특수 기호 등 부가적인 문자를 128개 추가할 수 있게 한 부호
- 확장 아스키는 1바이트내 8비트를 모두 사용함으로써 추가적인 문자 표현 가능
- 확장 아스키는 서로 다른 프로그램이나 컴퓨터 사이에 교환되지 못함
- 유니코드: 다국어 처리를 위한 표준
- 컴퓨터가 발전하면서 각 국가들은 자국의 문자를 표현하기 위하여 코드 체계를 만들어서 사용
- Character Set : 유니코드를 저장하는 변수의 크기를 정의
- 파일 인식 시 이 파일이 USC-2, UCS-4인지 인식하고 각 경우를 구분해서 모두 다르게 구현해야 하는 문제 발생
- 유니코드 인코딩 (UTF : Unicode Transformation Format)
- UTF-8 : web,
- UTF-16 : java,
- UTF-32 : unix
- python 2 버전대는 ASCII를 사용
#-*-coding:utf-8-*-, 3.x버전부터 UTF-8 사용 - 다른 인코딩 방식으로 처리 시 첫 줄에 작성하는 위 항목에 원하는 인코딩 방식을 지정해주면 됨
1.2 문자열의 분류
문자열은 크게 고정길이, 가변길이로 나눠지고 가변길이는 길이조절 문자열과 구분자 문자열이 있다. 길이조절 문자열은 자바에서의 문자열 형식이며 구분자 문자열 형식은 C언어에서의 문자열 형식이다.

1.2.1 C언어에서의 문자열 처리

1.2.2 java에서의 문자열 처리

1.2.3 python에서의 문자열 처리
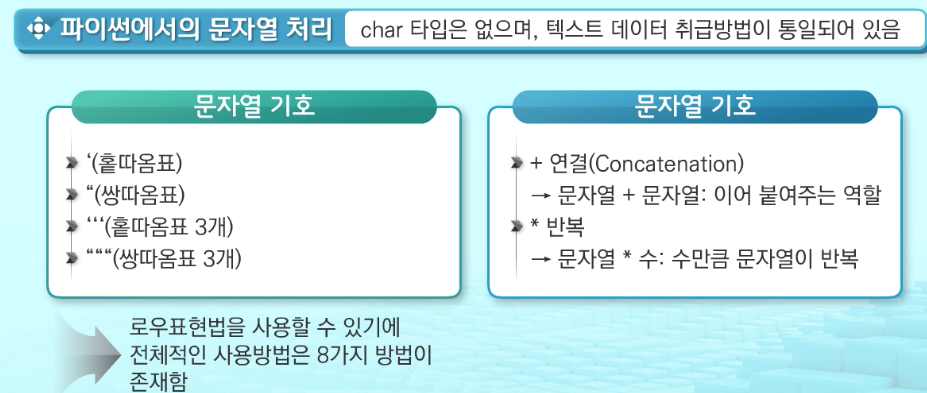
- 파이선에서 문자열은 시퀀스 자료형으로 분류되고, 시퀀스 자료형에서 사용할 수 있는 인덱싱, 슬라이싱 연산들을 사용할 수 있음
- 문자열 클래스에서 제공되는 메소드 :
replace(), split(), isalpha(), find() - 문자열은 튜플과 같이 요소값을 변경할 수 없음(immutable)
1.2.4 C와 Java의 Python의 String 처리의 기본적인 차이점
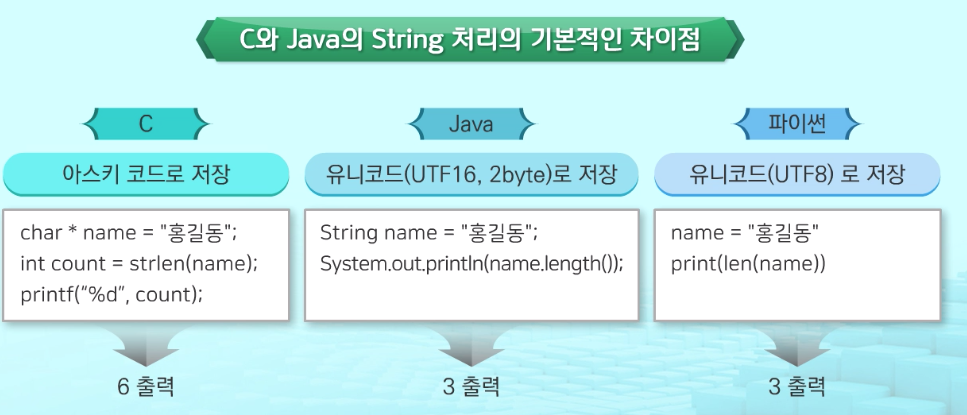
- C의 경우 홍길동이란 문자열 길이 출력하면 한글 문자 하나의 바이트수가 2바이트이고 아스키의 경우 1바이트이기 때문에 6이 출력된다.
1.3 문자열을 복사하는 알고리즘
-
C언어

-
python에는 한 개의 문자단위 처리는 없다
1.4 문자열 뒤집기
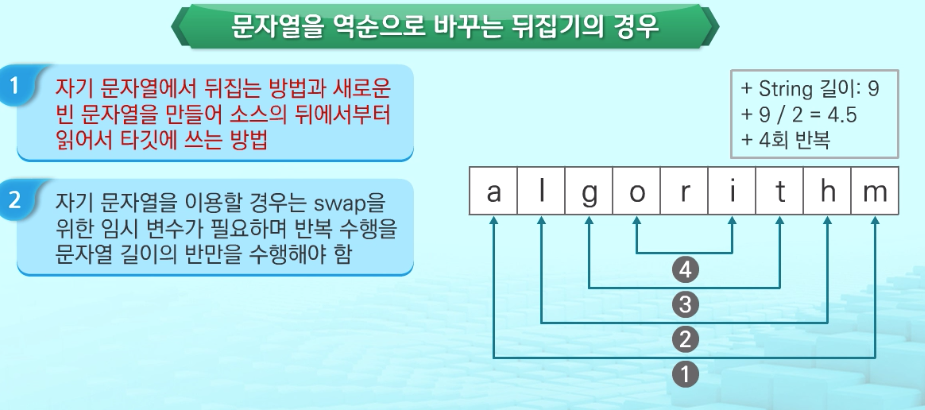
1.5 문자열 비교

1.6 문자열 숫자를 정수로 변환하기
-
C 문자열로 이루어진 숫자를 그대로 사용하면 예상과 다른 결과값을 출력 (코드체계 때문) -> 문자열을 정수로 변환하는 기능이 필요 (ex: atoi 함수)

-
Java, python

패턴매칭
패턴 매칭 알고리즘 : 본문에서 특정한 문자열을 찾는 것
- 고지식한 패턴 검색 알고리즘
- KMP 알고리즘
- 보이어 무어 알고리즘
-
고지식한 알고리즘(Brute Force) 본문 문자열을 처음부터 끝까지 차례대로 순회하면서 패턴 내의 문자들을 일일이 비교하는 방식을 동작
 -> 비교횟수가 너무 많은 문제
-> 비교횟수가 너무 많은 문제 -
KMP 알고리즘
불일치가 발생한 텍스트 문자열읠 앞 부분에 어떤 문자가 있는지를 미리 알고 있으므로, 불일치가 발생한 앞 부분에 대하여 다시 비교하지 않고 매칭을 수행
- 패턴을 전처리하여 배열 next[M]을 구해서 잘못된 시작을 최소화함
next[M]: 불일치가 발생했을 경우 이동할 다음 위치 -
시간 복잡도 : O(M + N)
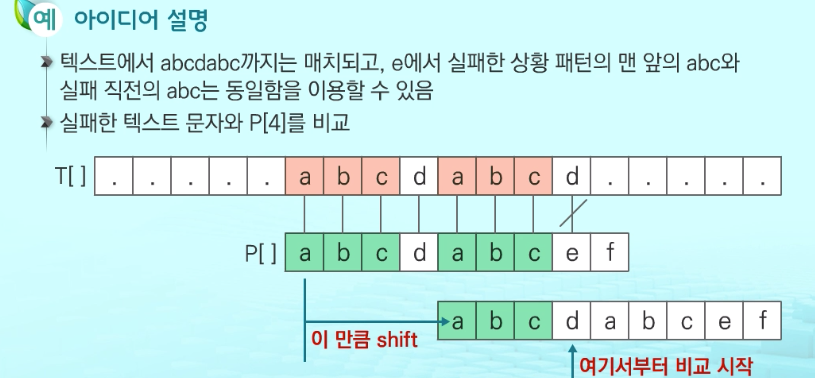
- 매칭이 실패했을 때 돌아갈 곳을 계산
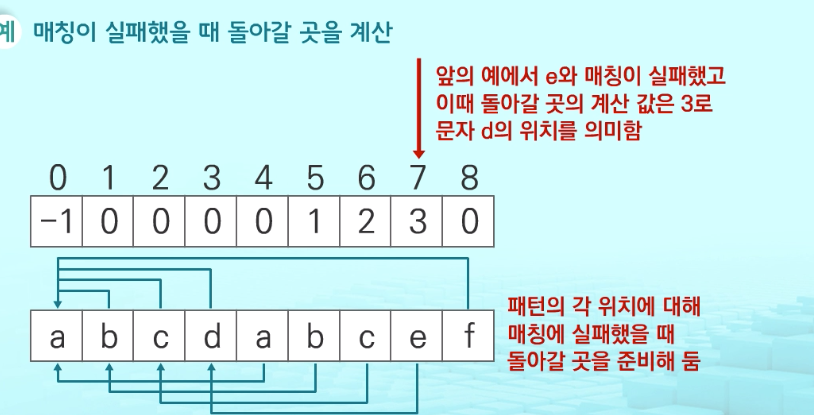
- 패턴을 전처리하여 배열 next[M]을 구해서 잘못된 시작을 최소화함
-
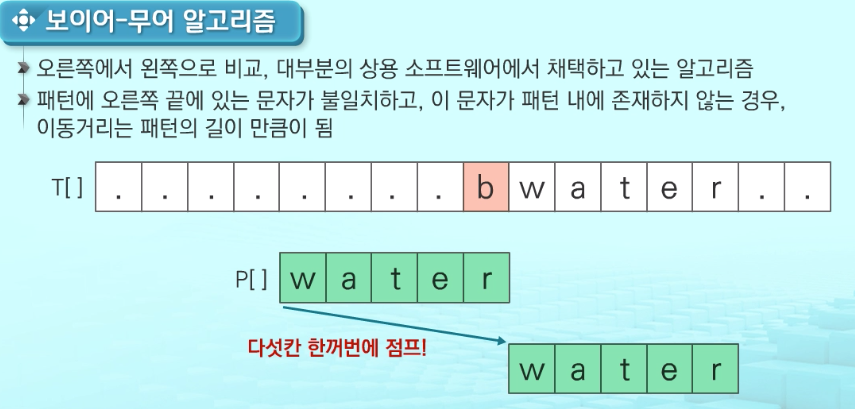
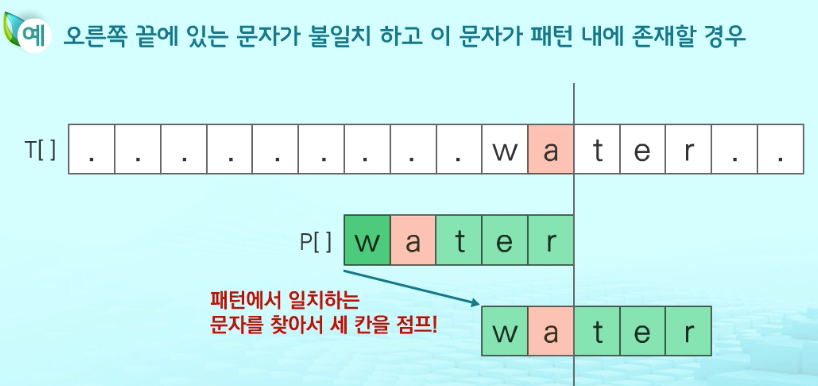
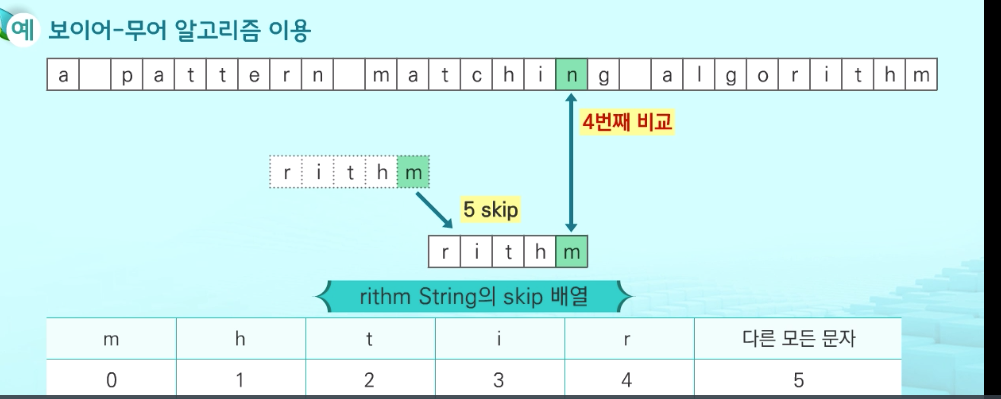
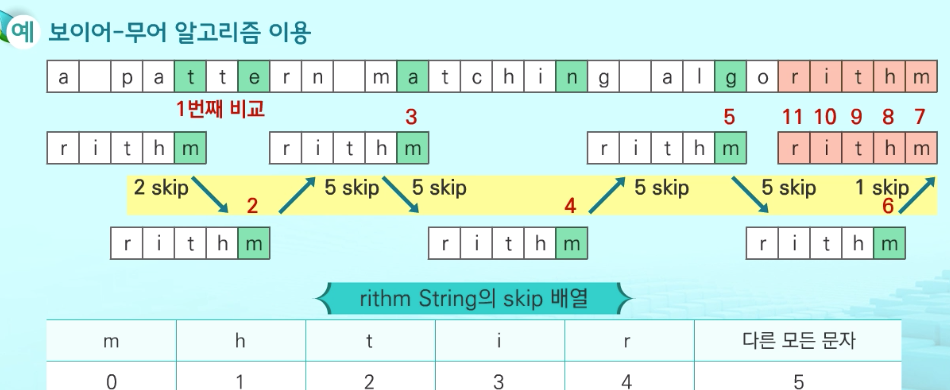
보이어-무어 알고리즘
오른쪽에서 왼쪽으로 비교, 대부분의 상용 소프트웨어에서 채택하고 있는 알고리즘
-
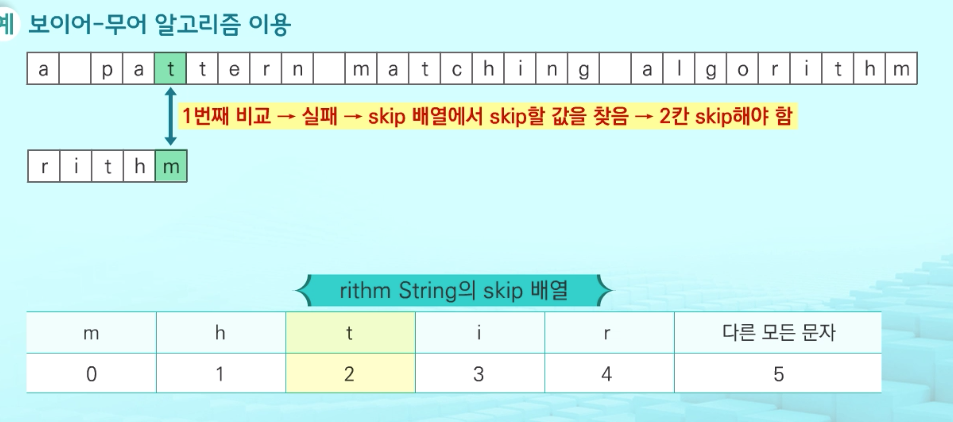
문자열 맻이 알고리즘 비교 찾고자 하는 문자열 패턴의 길이 m, 총 문자열의 길이 n,

참고자료 [SWE]https://swexpertacademy.com